
个税计算器
https://huangtairanpython.azurewebsites.net
功能:基于最新税率,在考虑四险一金和专项附加扣除的条件下,计算个人所得税和税后收入
个税计算器
https://huangtairanpython.azurewebsites.net
功能:基于最新税率,在考虑四险一金和专项附加扣除的条件下,计算个人所得税和税后收入
Mailgun提供了免费的邮件发送服务,适合拿来做通知提醒一类的服务。免费版默认支持每天发送多达300封邮件,最多可以发10,000封。
注册方法:访问 https://www.mailgun.com/email-api , 点Sign Up Free
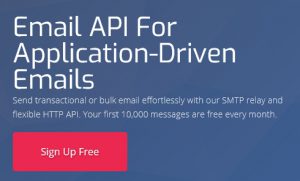
输入基本信息,包括要接收邮件的Email地址。不要勾选 add payment info now.
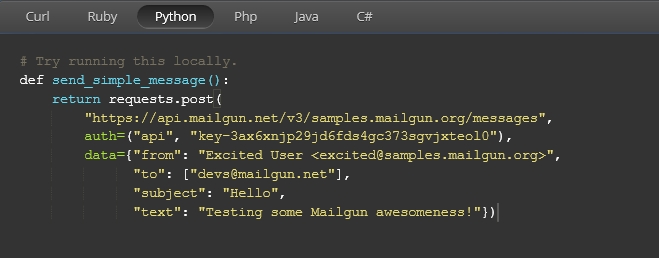
注册完毕,Mailgun会向你注册的邮箱发送API key,也会提供下图所示的调用代码,有多种语言可选。
这里选择了Python。人生苦短,我用Python。
下图是一个用Python程序爬取东方网新闻,并发送邮件的示例。
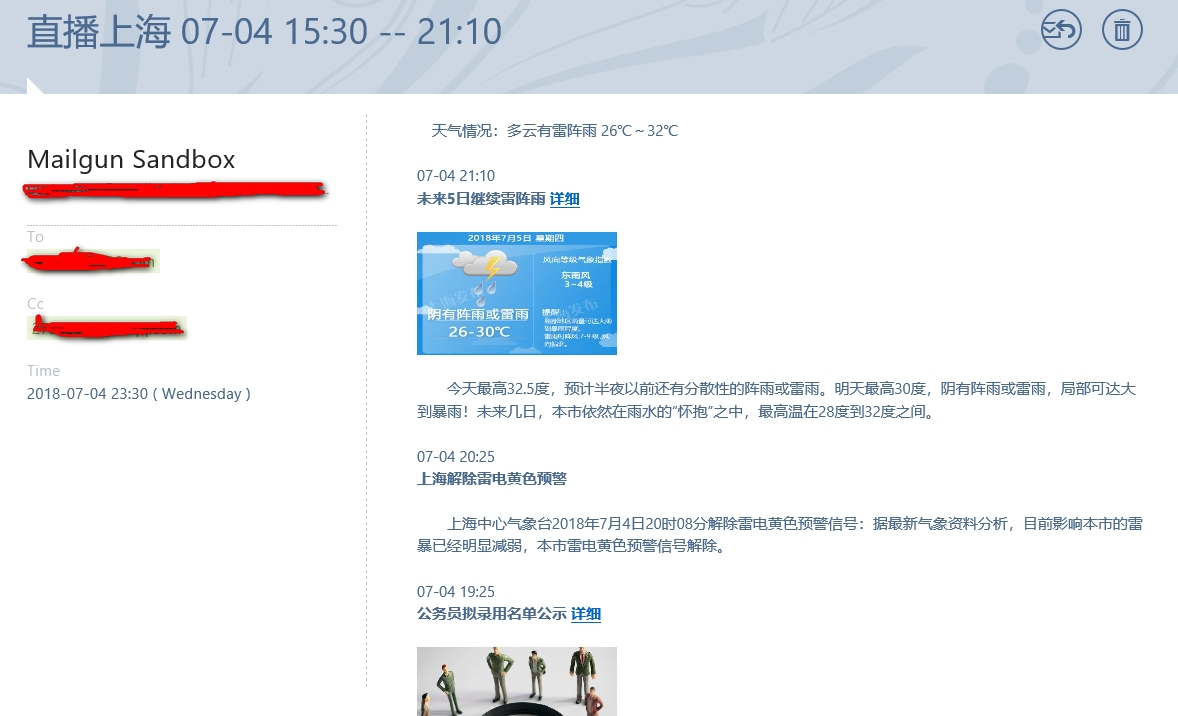
获取源代码请移步Github : https://github.com/TaylorHuang2017/Eastday_News
注:PEP = Python Enhancement Proposal (Python增强建议书,即Python开发规范)
本PEP详细说明了Python软件包要在选定的构建(Build)系统上运行时,应该如何指定其依赖关系。本规范引入了一个新的配置文件,用于指定软件包的构建依赖关系(假定今后的配置会使用相同的配置文件作为参考)。
当Python首次开发用于构建项目软件分发的工具时,distutils [1]是选定的解决方案。随着时间的推移,setuptools [2]越来越流行,它在distutils的基础上增加了一些功能。两者都应用了setup.py文件这样一个概念。项目维护人员通过执行这个文件来构建其软件的发行版(使得用户也能够安装上述发行版)。
distutils是Python标准库的一部分,所以,使用一个可执行文件来指定distutils下的构建条件是没有问题的。将构建工具作为Python的一部分意味着,项目维护人员如果要构建一个项目的发行版,无需担心setup.py有哪些外部依赖项。唯一的依赖项只是Python,因此没有必要指定任何依赖信息。
但是当一个项目选择使用setuptools时,像setup.py这样的可执行文件的使用就成了一个问题。你无法在不知道setup.py文件依赖关系的条件下执行它。可是,目前还没有标准的方法,在不执行存储着依赖信息的setup.py文件的情况下,自动地了解它具体有哪些依赖项。这就形成了一个悖论:你不运行这个文件,你就无法知道它的内容;你不知道这个文件的内容,就无法运行它。
setuptools尝试用它的setup() 函数的setup_requires参数来解决这个问题[3]。 此解决方案有许多问题,例如:
这导致了setup_requires很少被人使用的情况,在这种情况下,项目倾向于只是在多个setup.py文件之间复制和粘贴代码片段,或者完全跳过,仅仅只在某个地方记录好–希望用户在尝试建立或安装他们的项目之前,已经手动安装好的内容。
所有这一切使得pip [4]假定在执行setup.py文件时setuptools是必需的。但问题在于,如果另一个项目像setuptools那样开始在社区中获得关注,这个项目就没有可扩展性。如此一来,会阻止其他项目获得应有的关注。因为当pip无法推断出项目需要的是除setuptools以外的某个东西时,使用setuptools便会产生冲突。
本PEP试图在特定文件中、以一种声明式的方式显式列出项目构建系统的最小依赖关系,从而解决当前的状况。此举允许项目列出它必须具有何种构建依赖关系。例如,源代码签出到wheel,同时不落入setup.py所形成的悖论中。即,工具无法推断项目需要自行构建的东西。实施本PEP将允许项目预先指定他们依赖的构建系统,以便像pip这样的工具可以确保所有依赖条件已经安装,以便运行构建系统来进行构建。
为了提供更多的上下文和推动本PEP,可以把所需的(大体)步骤看成是生成一个手工项目的过程:
本PEP涵盖了第2步。 预计未来的PEP将包括第3步,包括如何使构建系统动态指定构建系统执行其工作所需的更多依赖性。 但是,本PEP的目的是为构建系统指定要开始运行所需的最低要求。
构建系统的依赖关系将存储在一个名为pyproject.toml的文件中,该文件以TOML格式编写[6]。选择这种格式是因为它可供人来使用(不像JSON [7]),它足够灵活(不像configparser [9])起源于某个标准(也不像configparser [9]),不过于复杂(不像YAML [8])。 TOML格式已被Rust社区用作其包管理器的一部分[14],据私人电邮所述,他们对选择TOML感到非常满意。关于为什么不选择各种替代品的更详细的讨论可以阅读以下其他文件格式的部分。
在配置文件中将会有一个[build-system]表来存储与构建相关的数据。最初,表中只有一个关键字是有效的和必需的:requires。该键将包含一个字符串列表的值,代表执行构建系统所需的PEP 508依赖体哦阿健(意味着执行setup.py文件需要哪些依赖条件)。
以下的JSON架构[15]将与数据格式匹配,表示了某个特定类型的结果数据。这些数据来自于仅供演示用的TOML文件:
对于绝大多数依赖setuptools的Python项目,pyproject.toml文件会是这个样子:
[build-system]
# Minimum requirements for the build system to execute.
requires = [“setuptools”, “wheel”] # PEP 508 specifications.
由于目前社区中setuptools和wheel的使用非常广泛,所以当pyproject.toml文件不存在时,构建工具将使用上面的示例配置文件作为它们的默认语义。
所有其他顶级密钥和表格保留供将来由其他PEP使用,但[工具]表格除外。 在该表中,只要工具使用[tool]中的子表,工具就可以指定配置数据,例如, 该快速工具会将其配置存储在[tool.flit]中。
我们需要一些机制来在工具中分配tool.*命名空间中的名称,以确保不同的项目不会尝试使用相同的子表并发生冲突。 我们的规则是项目可以使用子表工具。$ NAME当且仅当他们拥有Cheeseshop / PyPI中的$ NAME条目时。
语义版本密钥
为了将来验证配置文件的结构,最初提出了语义版本密钥。 默认为1,这个想法是,如果任何语义更改为先前定义的键或表发生不向后兼容,则语义版本将增加到一个新的数字。
但最终却认定这是一个不成熟的优化。 期望的是,在配置文件中对语义上预先定义的内容的更改将是相当保守的。 在发生向后不兼容的变化的情况下,可以使用不同的名称作为新的语义,以避免破坏旧的工具。
一个嵌套更深的命名空间
这个PEP的早期草案有一个顶级[包]表。 这个想法是为语义版本方案强加一些范围(请参阅语义版本关键字为什么这个想法被拒绝)。 由于需要删除范围,因此拥有顶级表的重要性变得多余。
其他表名
[build-system]表的另一个名字是[build]。 替代名称较短,但并未表达信息存储在表中的意图。 在distutils-sig邮件列表上进行投票后,当前名称才能胜出。
其他文件格式
提出了其他几种文件格式供考虑,都因各种原因而被拒绝。 关键要求是该格式可以由人进行编辑,并且具有可以通过项目轻松销售的实施。 这彻底排除了某些格式,如对人类不友好的XML,而且从未认真讨论过。
JSON
JSON格式[7]最初被考虑但很快被拒绝。 尽管作为基于字符串的人类可读的数据交换格式非常好,但语法本身并不适合人类轻松编辑(例如,语法比所需的更冗长而不允许评论)。
提议的数据的示例JSON文件将是:
YAML
YAML格式[8]被设计为JSON的超集[7],同时更易于手工操作。 YAML有三个主要问题。
一个是规范太多:如果打印在letter尺寸的纸上,则为86页。这就使得有人可能会使用YAML的功能与一个解析器一起工作,而不是另一个解析器。有人建议在一个子集上进行标准化,但这基本上意味着要创建一个特定于该文件的新标准,这个标准是不容易长期处理的。
二是YAML默认本身并不安全。该规范允许在处理配置数据时最好避免代码的任意执行。当然可以避免这种行为 – 例如,PyYAML提供了一个safe_load操作 – 但是如果任何工具不小心使用load,那么它们会自行开启任意代码执行。虽然这个PEP专注于构建固有涉及代码执行的项目,但其他配置数据(如项目名称和版本号)最终可能会在相同的文件中随意执行任意代码。
最后,最流行的YAML的Python实现是PyYAML [10],它是一个包含几千行代码的大型项目,也是一个可选的C扩展模块。虽然本身并不一定是个问题,但对于像pip这样的项目来说,这更像是一个问题,因为他们很可能需要将PyYAML作为依赖项供应商,以便完全独立(否则,最终会导致您安装需要安装工具的工具才能正常工作)。 PyYAML的一个概念验证重新工作已经完成,看看有多容易的可能供应一个简单版本的库,这表明它是一种可能性。
一个YAML示例文件:
build: requires: - setuptools - wheel>=0.27
Configparser
一个基于configparser INI风格配置文件考[9]。 不幸的是,没有关于什么configparser接受的规范,导致版本之间的支持倾斜。 例如,Python 2.7中的ConfigParser接受的内容与Python 3中的configparser接受的内容不同。 虽然可以标准化Python 3接受的内容,并简单地供应configparser模块的backport,但这确实意味着此PEP必须编码,所有项目希望使用configparser的backport才能使用此PEP指定的元数据。 这是过度限制性的,如果有人不知道预期特定版本的configparser会导致混淆。
一个示例INI文件是:
[build]
requires =
setuptools
wheel>=0.27
Python文字
有人提议使用Python文字作为配置格式。 该文件将在顶层包含一个字典,数据全部在该字典中,并且由键定义部分。 所有的Python程序员都会习惯这种格式,隐含的情况是没有第三方依赖来读取配置数据,如果用ast.literal_eval()进行解析,它可能是安全的[13]。 Python文字可以与JSON相同,同时支持尾随逗号和注释。 另外,Python的更丰富的数据模型可能对未来的某些配置需求非常有用(例如非字符串字典密钥,浮点数与整数值)。
另一方面,python文字是Python特有的格式,并且预计这些数据可能需要通过不是用Python编写的打包工具等来读取。
提议数据的Python文字文件示例如下:
# The build configuration
{“build”: {“requires”: [“setuptools”,
“wheel>=0.27”, # note the trailing comma
# “numpy>=1.10” # a commented out data line
]
# and here is an arbitrary comment.
}
}
其他几个文件名在考虑后并未接受(这是一个非常相似的话题,最终决定主要是根据喜好)。
pysettings.toml
最合理的选择。
pypa.toml
虽然参考PyPA [11]是有道理的,但这是一个有点用处的术语。没有特定领域的知识,最好让文件名有意义。
pybuild.toml
从这个PEP的限制性角度来看,这个文件名是有意义的,但是如果有任何非构建元数据被添加到文件中,那么名称就不再有意义了。
pip.toml
工具特定。
meta.toml
太通用;项目可能希望拥有自己的元数据文件。
setup.toml
在保持setup.py的传统感谢的同时,它不一定与未来文件可能包含的内容相匹配(例如,.e.g知道项目名称是否是其设置的一部分?)。
pymeta.toml
新手对编程和/或Python不太明显。
pypackage.toml&pypackaging.toml
命名“什么是包”(项目与命名空间)的合并。
pydevelop.toml
该文件可能包含非特定于开发的细节。
pysource.toml
与源代码没有直接关系。
pytools.toml
由于该文件(当前)针对项目管理,因此具有误导性。
dstufft.toml
个体相关性太大
原文地址:https://www.python.org/dev/peps/pep-0518/
译者:首席IT民工
本文透过大量收集自Python开发者调查的数据,揭示了有关Python编程语言的最新使用情况和发展轨迹。
Python正变得越来越受欢迎,在科技新闻中引起了人们更多的关注。有报道说,更多的女高中生们正在将Python应用于计算机工程的学习;Python被推荐为大学计算机入门课程的编程语言。 此外,Stack Overflow的2018年开发者调查显示,Python是大多数人想学习的编程语言。 Python被广泛用于网络,从简单的个人网站,到全世界大型银行里的数据挖掘和机器学习。
是什么让Python如此特别? Python开发者是哪些人? 它为什么如此受欢迎? 为了回答这些以及其他许多重要的问题,JetBrains和Python软件基金会(Python Software Foundation,PSF)合作,针对使用Python作为主要或次要语言的人群开展了一项调查。 到目前为止,还没有人做过针对Python的专项研究,以期了解不同开发人员是如何使用它的,有哪些组件促进了它的使用,以及是什么让它成为了最受欢迎的语言之一。
我们调查的目标是确定Python的最新趋势,并一窥Python开发界的全貌。抱着这一目的,我们着手研究了以下问题:
该调查于2017年10月发布。这里是我们对结果所做的汇总,你也可以从Python开发者调查2017年结果的网站上挖掘更多的图表和原始数据。
在我们查看相关数据和见解之前,有必要回顾一下调查所采取的方法,包括:调查是如何派发的,采取了哪些措施来避免潜在的偏见,并确保调查不倾向于任何特定的工具,技术,库,或者国家。
我们将调查发送给几个独立的团体,包括订阅了PSF邮件列表,博客,Slack,LinkedIn和Twitter的人员。我们还在一些访问量最大的Python.org页面上推广了该项调查,并通过阅读文档进行了公布。大部分回复(62%)来自Python.org上的广告横幅;其他主要来源是PSF博客和Twitter帖子。我们没有利用产品、服务或供应商相关的渠道,以防止调查结果倾向于任何特定的工具或技术。
调查深受社区的欢迎,回复率超过预期。在开放期间,收到的回复超过了1万份。我们在做调查分析时过滤掉了不完整和重复的回复,留下来的数据集包括了来自150多个国家的9,532名应答者。对于如此大的样本,描述统计误差的保守置信区间仅为1%,意味着所有结果都具有统计显著性。我们实现了调查的主要目标:收到了准确可靠的数据!
开启Python世界之旅的第一步,让我们来聊聊最令人兴奋的事儿 — 和Python语言及其应用程序相比,Python社区也呈现出同样的多元化。
虽然Python用户的年龄范围很广,但是大多数受访者的年龄在20岁左右,四分之一在30多岁。有趣的是,几乎五分之一的Python用户年龄在20岁以下。如果我们将Python开发人员的年龄范围,与Stack Overflow在其最新调查中确定的一般开发人员的年龄范围进行比较,分布情况比较相似。区别在于,Python调查中,年龄在18岁以下的开发者稍微多一些。原因在于,很多中学和大学的学生在使用Python,而且Python常常被选作第一门语言。
超过一半的受访者是全职的开发人员,每五名开发人员中就有一位担任数据分析师,架构师,或团队负责人。与Stack Overflow的调查相比,我们可以看到:Python开发者比一般开发者更少可能全职工作(52%的Python开发人员与74%的开发人员),更有可能为自己工作,或成为自由职业者(Python开发人员占13%,所有开发人员占9.7%)。
Python调查的受访者呈现出各种不同的经验; 22%的人拥有不到一年的经验,超过11年经验的人也是这个比例,而在这两者之间的分布趋于平滑。这表明新手和经验丰富的开发人员之间保持了良好的平衡,使Python成为了可持续发展的语言。
值得注意的是,Python比其他语言的平均新手比例高得多。 根据Stack Overflow数据,30%的开发人员拥有不到两年的专业经验,而Python开发人员调查中的这一比例为41%。
大型的Python开发团队中并不多见。 在我们的调查中,56%的Python开发人员表示他们独立开发项目,40%的人通常在2到7人的团队中工作。 大约一半的受访者在从事一个主要项目的同时还有几个小项目,而四分之一的人则一次只从事一个项目。
2016年,JetBrains在没有PSF参与的情况下举办了一次Python开发者调查。 虽然JetBrains在2016年的样本规模很大,但其调查主要通过自己的渠道进行推广,这自然吸引了PyCharm用户中的更大份额 – 约50%的PyCharm用户和50%的使用其他编辑器的用户。 为了减少不可避免的偏差,2016年的调查没有比较不同代码编辑器的用户数量。 尽管2016年的调查结果存在偏差,仍然值得比较一下2017年和2016年的一些调查结果。 例如,在2016年的调查中,45%的人表示独立完成自己的项目,51%的人则是团队工作。 2017年调查中的这一比例不同也许是因为,有大量的新手,且Python是他们的第一语言,以及数据科学家的数量和现在使用Python的Web开发者的数量旗鼓相当。
正如我们上面所写的,在Stack Overflow的2018年开发者调查中,Python是最理想的语言(即调查者最有兴趣学习的语言);这是Python连续第二年获得该排名。 Python用户在排名最高的编程语言中排名第三。这些事实与Python就业市场是什么关系呢?
尽管Python开发人员调查并未专门提出工作受欢迎度,但我们可以从Python开发人员需要的其他资源中,收集世界范围内的各种工作信息。包括机器学习,数据库,数据分析,云基础设施,设计,站点可靠性/测试,网络抓取,安全性,移动开发,API等等。根据jobs.python.org上列出的职位,机会倾向于国际化需求,尤其是在英国地区。
在任何主要求职网站搜索“Python开发人员”,往往会返回数千个就业机会。 2018年3月,美国Python开发者在美国的平均工资(根据实际数据)为115,835美元。这么高的平均工资表明,许多公司正在竞相雇佣知识渊博的Python开发人员。这进一步说明Python确实是一种广受欢迎的技能。
Python与美国最好的工作 — 数据科学也有关系(基于2018年4月的Glassdoor.com)。大约五分之一的数据科学工作涉及Python,包括NumPy,Pandas和Matplotlib库。
几乎五分之四的Python开发者认为Python是他们的主要语言,比JetBrains 2016年调查的75%增加了4%。
各种研究表明,Python开发人员的数量以及使用Python作为主要语言的开发人员的份额正在逐年稳步增长。 在Stack Overflow的调查中,Python的受欢迎程度从2017年初的32%上升到今年年底的38.8%。 这可以通过Python数据科学的迅速普及来解释,因为这部分用户的增长速度远远快于其他用户。
Python经常与其他语言一起使用:
所有使用Python作为主要语言的开发人员中有一半还使用JavaScript。 79%的网页开发人员使用JavaScript,但只有39%涉及数据分析或机器学习。
对于那些使用Python作为辅助语言的用户来说,细分情况略有不同,因为使用JavaScript(46%)和更多使用C / C ++(42%),Java(41%)和C#(24%)的用户较少。
Python开发类型
为了确定最流行的Python开发类型和它们的交集,我们提出了两个类似的问题:“你用Python做什么?” 受访者可以选择多个答案,以及“你最喜欢用Python干什么?” 受访者只能选择一个答案。 结果显示,科学方面的开发现在像网络开发一样受欢迎:有一半的受访者从事数据科学项目,另一半是网站开发。
根据受访者是否使用Python作为主要或次要语言,回复有所不同:使用Python作为其主要语言的人中有54%参与了Web开发,而那些认为Python是其次要语言的人中有33%参与了Web开发。 这种差异对于数据分析,机器学习和其他类型的开发来说不太重要。
许多Python开发人员扮演多种角色。 他们承担最多的角色有:
数据分析和机器学习的交叉是预料之中的,网络开发和数据分析/机器学习之间的交叉却值得关注。
当被问及他们从事的主要开发类型时,26%的Python用户选择网页开发,超出了数据分析的范围(据报道为18%)。
但是,如果我们将18%进行数据分析的人与9%主要角色是机器学习的人结合起来,那么我们知道27%的人主要从事科学开发。 这意味着数据科学家使用Python的人数与网络开发人员数量一样多。
有趣的是,当JetBrains在2016年进行了Python开发者调查时,有38%的受访者认定为Web开发人员,只有21%认为是科学开发人员。 这可能是Python开发人员数据科学家迅速增长的证据。
比较使用Python作为主要语言与辅助语言的趋势之间的趋势,网站发展差距最大(29%为主,15%为次要)。 数据分析和机器学习的差别要小得多。 相反,更多的DevOps和系统管理员使用Python作为辅助语言(13%)而不是主要语言(8%)。
Python开发者调查中,最令人感兴趣的问题是Python世界中,网络开发者与数据科学家的比例。 我们要求受访者估算使用Python的网络开发人员和数据科学家之间的比例。 受访者可以根据自己的经验,看法和一般“直觉”来回答。 因为我们明确地询问了开发的类型,并且样本规模足够大以具有统计显著性,所以我们可以将社区的看法与现实进行比较。
更多受访者(57%)认为网络开发者比数据科学家更普遍,而只有33%认为相反。
根据之前部分显示的数据(26%网络开发,27%科学开发为主要活动),真实的比例是1:1。
只有九分之一的受访者猜对了这一点; 大多数人低估了Python数据科学用户的数量。 Web开发通常被认为是Python的主要应用。 虽然这在几年前是真的,但Python数据科学家的数量正在快速增长,并且已经与Web开发人员的数量保持一致。
我们问,“你使用最多的是Python的哪个版本?” Python 3遥遥领先,是75%,而使用Python 2作为主要解释器的仅占25%。 Python 3正在迅速增长; 在2016年的调查中,60%的人使用Python 2和40%的Python 3. Python 2的使用正在下降,因为它没有得到积极发展,没有获得新的功能,并且在2020年后不再维护。
值得注意的是,70%的网络开发人员使用Python 3,而数据分析师中有77%,机器学习专家中有83%。 这可能是因为许多Web开发人员在转换到Python 3时仍需要维护遗留代码,并且许多数据分析师和机器学习专家最近才加入Python生态系统,直接选择了Python 3。
我们还询问开发人员他们如何安装和更新他们的Python文件。
70%的人从python.org安装Python,或者使用操作系统提供的软件包管理器,如APT和Homebrew。
Django是最流行的框架; 41%的Python开发人员使用它。
科学软件包,如NumPy,Pandas和Matplotlib合在一起紧随其后,达到39%。 其他流行的框架和库有Requests,Flask,Keras / Theano / TensorFlow / Scikit-learn等。 TensorFlow和Django在StackOverflow的最受喜爱和最需要的技术之列。
Django被76%的Web开发人员选为第一框架,而在数据科学领域工作的人中只有31%。 奇怪的是,29%的网页开发人员正在使用科学库。 这证实了两个角色之间的巨大重叠。
当被问及除Python以外的技术时,Jupyter Notebook的排名最高为31%,考虑到大量数据科学开发人员,这很有意义。 Docker仅以29%的速度落后2%。 按角色拆分,Docker被47%的参与Web开发的人使用,只有23%的数据科学家使用Docker。 同样,Web开发人员使用Amazon Web Services,Google App Engine,Heroku等云平台的频率是数据科学家的两倍。
比较2016年的调查结果和2017年的调查结果,Django和Flask这两个最流行的Web框架已经丢失了一些份额。 (2016年,Django的使用率为51%,2017年为41%; 2016年的Flask使用率为40%,2017年为32%)。 同时,科学库和技术框架的使用也在增长。 2016年,Anaconda,NumPy和Matplotlib(合并)的使用率为36%; 在2017年底,NumPy,Pandas,Matplotlib,SciPy和类似项目的使用率为39%,Anaconda使用率为25%。
当被问及他们使用哪种云平台时,云使用受访者首先将AWS排在了67%。 Google App Engine,Heroku和DigitalOcean的使用要少得多。 AWS在Stack Overflow的调查中也高度评价最喜爱和最受欢迎的平台。 我们可以列出的云平台的可能回答很有限; “其他”类别收集了13%的响应,包括Linode,PythonAnywhere,OpenShift和OpenStack。
当我们询问在Python开发中对于开发实践,工具和功能的使用时,回复最多的地方是代码自动完成,代码重构,编写单元测试以及使用Python项目的虚拟环境。 NoSQL数据库,Python分析器和代码覆盖工具是最罕用的。 这些结果与2016年的数据非常相似:
为了找出最受欢迎的编辑器和IDE,我们提出了两个问题:“您在Python开发中考虑过哪些编辑器/ IDE?” 并允许多个答案,以及一个单一答案的问题,“你当前Python开发使用的主要编辑器是什么?” 基于对这个问题的8,000多个回复,PyCharm是最流行的工具,其次是Sublime,Vim,IDLE,Atom和VS Code。
注:我们采取了大量步骤来消除偏见,并确保调查不倾向于使用任何特定的工具。 要详细了解调查方法以及用于分派调查的渠道,请参阅调查结果网站的原始数据部分。
Web开发人员在编辑器的喜好上与数据科学家略有不同。 Web开发人员非常喜欢PyCharm专业版,Sublime文本和Vim,而数据科学家显然更喜欢PyCharm社区版,Jupyter Notebook和Spyder。
当我们问道:“在Python编程中,你考虑过哪些编辑器/集成开发环境?” 我们了解到Web开发人员考虑最多的是Sublime Text(47%),其次是Vim(39%)和Atom(32%)。 科学开发人员最常考虑Jupyter Notebook(42%),其次是PyCharm社区版(39%),崇高文本(31%)和Vim(26%)。
我们还发现,大多数开发人员每天都使用他们的编辑器,大约五分之一每周使用他们的编辑器。
与Python及其社区的开源哲学一致,我们已经向公众提供了原始数据,我们欢迎进一步的分析和结论。我们打算在2018年和未来几年重复这项调查。我们的目标是让每年的调查差不多,以便完成纵向的数据分析。
在解析原始数据之前,请注意以下几点:数据是匿名的,没有个人信息或地理位置详情。此外,对所有开放式领域进行了裁剪,以防止通过逐字评论来识别任何个人受访者。为了帮助他人更好地理解调查的逻辑,我们用英语共享数据集,调查的问题和所有调查逻辑。我们使用不同的排序方法来回答选项(字母,随机,直接)。每个问题中都指定了使用答案选项的顺序。
我们很乐意了解您的发现!请在Twitter或其他提供@ jetbrains和@ThePSF的社交媒体上与#pythondevsurvey2017#标签分享。我们也乐于接受建议和反馈,以便下次改进。欢迎在这里提出任何意见或问题。
2017年Python开发者调查表示了社区的基准。一些更重要的关键点有:
我们希望调查结果阐明了Python开发者社区的现状,让你纵览全局,并解答了一些疑问。
原文地址:https://dbader.org/blog/python-ipaddress-module
作者:Jon Crawfurd
副标题:本文介绍了Python 3.3以上版本中用于处理IPv4和IPv6地址的ipaddress模块。
在本文中,我们会看一看Python 3.3及更高版本中提供的ipaddress模块。 本教程旨在为想知道如何在Python中解析和使用IP地址的网络工程师们提供一个简要参考。
在这篇概述中,你将了解到:
从大的方面来说,IPv4地址和IPv6地址具有相同的目的和功能。但是,由于每个协议的地址结构存在很大差异。本教程用了不同的部分,来分别讨论IPv4和IPv6。
当今的互联网中,IPv4协议承担了绝大部分的IP处理任务,在不久的将来也依旧如此。 尽管IPv6所带来的规模和功能方面的增强对未来互联网不可或缺,正在被逐步应用,但是到目前为止,应用率仍然很低。
一个IPv4地址由32位组成,分为四个“八位组”。 “八位组”一词用于标识一个八位结构来代替更常见的术语“字节”,但它们的定义相同。四个八位组被称为octet1,octet2,octet3和octet4。这是一个“点分十进制”格式,其中每个八位组对应一个从0到255的十进制值。
IPv4地址示例:192.168.100.10
IPv4地址示例(CIDR表示法):192.168.100.10/24
“/24”是CIDR表示法,表示32位的前24位用于标识地址的网络部分。 记住每个八位组长度为8位,这意味着前三个字节(3×8 = 24)标识网络(192.168.100.x),地址的其余八位标识节点(x.x.x.10)。
CIDR表示法可以是从 /8位 到 /30位的任何值,偶尔有 /32位(/31无效),但通常使用/24。 例如,你的家庭网络,或你的学校或公司网络很可能用/24 CIDR来表示。
用于表示网络标识的早期术语是子网掩码,其中CIDR表示为单独的点分十进制数。 例如,一个/24 CIDR相当于一个网络掩码255.255.255.0。
IPv6地址长度为128位,与IPv4地址中的32位相比,有显著的增加。 IPv4和IPv6之间有很多不同之处,但最大的区别在于寻址结构。 额外的长度提供了可支持的网络和主机数量的指数级增长。
IPv6地址示例:2001:db8:abcd:100::1/64
在IPv4地址使用点分十进制格式的情况下,IPv6协议使用十六进制表示法。 IPv6地址中的每个位置表示4个位,其值从0到f,按以下方式组织:
所有的IPv6地址结构都使用CIDR表示法来确定有多少前导位用于网络标识,其余部分则用于主机/接口标识。考虑到是128位,产生的组合有很多。
ipaddress模块是按照CIDR表示法设计的,由于其简洁易用,受到人们的推荐。 ipaddress模块还包含了一些方法,用于在必要的情况下还原子网掩码。
IPv4地址的最初定义中包含一个“类”,这个“类”由第一个八位组中的地址范围所定义。 ipaddress模块不识别IPv4类,故在本教程中不会涉及。
ipaddress模块包含三个特定的IPv4地址对象类型:
“主机”和“接口”之间的主要区别在于主机或ip_address对象不包含CIDR表示法,而ip_interface对象包含CIDR表示法:
ipaddress.ip_address() 工厂函数用于创建ip_address对象。它会根据传入的值自动确定是创建IPv4还是IPv6地址(IPv6地址将在本教程的后面部分讨论)。 如上所述,这个对象表示一个数据包在穿越不需要CIDR的网络的过程中,所发现的IP地址。
在多数情况下,用于创建ip_address对象的值将是一个字符串,格式为IPv4点分十进制,如图所示:

或者,IPv4地址可以以二进制形式输入,如完整32位二进制值的十进制值,或按照此例,以十六进制格式输入:

第一个例子使用完整的32位地址,第二个例子是32位地址的十进制值。 两者都很笨拙,容易出错且没什么太大的价值。 第三个示例使用十六进制值,这可能很有用,因为解析或嗅探中的大多数数据包,都以十六进制格式表示。
ipaddress.ip_interface() 工厂函数用于创建ip_interface对象,该对象根据传入的值自动确定是创建IPv4还是IPv6地址(IPv6地址将在本教程的后面部分讨论)。
如前所述,ip_interface对象表示在正确处理数据包所需的CIDR(或掩码)所在的主机或网络接口上找到的IP地址。

在创建ip_interface选项时可以使用与ip_address选项(二进制,十进制值,十六进制)相同的选项。 但是,唯一通过CIDR表示法或掩码来有效创建ip_interface的办法,是使用点分十进制IPv4地址字符串。
ipaddress.ip_network()工厂函数用于创建ip_network对象,该对象根据传入的值自动确定是创建IPv4还是IPv6地址(IPv6地址将在本教程的后面部分讨论)。
IP网络定义:包括了一个网络或子网的连续IP地址范围。 例如:
创建ip_network对象遵循与创建ip_interface对象相同的语法:

在上面的例子中,使用的网络地址必须是一个有效的网络地址,它是构成网络的IPv4地址范围中的第一个地址。 否则,Python将抛出一个异常:

在使用主机或路由器接口时,通常需要确定网络地址。 可以经由计算得出,但是需要几个步骤,可以使用strict = False选项(strict = True是默认值)在一个步骤中完成。

在上面的例子中,ip_interface地址是已知的(192.168.100.10),但不是接口所属的ip_network。 使用strict = False选项,计算ip_network地址(192.168.100.0/24)并将其填充到ip_network对象中。
与IPv4一样,ipaddress模块使用与IPv4相同的三种基本工厂功能。 包括:
由于详细信息在IPv4部分中已经介绍,在此仅作简要描述。
ipaddress.ip_address() 工厂函数用于创建ip_address对象。 它会根据传入的值自动确定使用IPv6地址格式。 请注意,CIDR表示法未与ip_address函数一起使用。
在大多数情况下,用于为IPv6创建ip_address对象的值将是根据此示例的IPv6四进制/六进制格式的字符串:

与IPv4一样,可以使用完整的二进制,十进制或十六进制值创建IPv6地址对象。 对于IPv4地址,32位难以处理,而对于128位IPv6地址来说更是尴尬。 实际上,预计八个四重组表示的字符串将是一般形式。
ipaddress.ip_interface() 工厂函数用于创建ip_interface对象,该对象根据传入的值自动创建IPv6地址。 请注意,函数中必须包含CIDR表示法。

ipaddress.ip_network() 工厂函数用于根据传入的值为IPv6创建一个ip_network对象。
与IPv4一样,IPv6网络被定义为可分配给特定主机或路由器接口的一系列连续IP地址。
使用我们以前的示例2001:db8:abcd:100:: /64,/64 CIDR指定四个四重组构成完整的网络标识。 请记住,前三个四重组是IPS分配的全局ID,第四个四重组识别内部子网编号。 64位的余额用于从“0000:0000:0000:0001”到“ffff:ffff:ffff:fffe”的范围内的主机标识。
与IPv4寻址一样,IPv6子网中的第一个和最后一个地址不能用于主机寻址。 给定一个/ 64 CIDR,这意味着有2到2的64次方(减2)可能的主机地址,这意味着从数学角度,每个网络/子网有18,446,744,073,709,551,614个可能的主机地址。

上述全局地址分配如下:
这里是一些额外的资源,以便你进一步了解Python中的ipaddress模块:
本文的扩展PDF版本以及其他信息https://dbader.org/static/img/ipaddress-module-introduction.pdf
ipaddress模块文档https://docs.python.org/3/library/ipaddress.html
ipaddress模块介绍https://docs.python.org/3/howto/ipaddress.html
维基百科 – IPv4https://en.wikipedia.org/wiki/IPv4
维基百科 – IPv6https://en.wikipedia.org/wiki/IPv6
原文地址:https://blog.python.org/2018/04/pip-10-has-been-released.html
作者:Paul Moore
译者:首席IT民工
我代表Python包管理局(Python Packaging Authority),很高兴在此宣布:pip10刚刚正式发布了。这个版本是几个月以来社区工作的结晶。
要安装pip 10,请运行:
python -m pip install –upgrade pip
或者,按照https://pip.pypa.io/en/latest/installing 所述,使用 get-pip. 如果你使用的pip版本来自于分发供应商,会由供应商在适当的时候提供升级(你也可以选择在虚拟环境中使用pip 10)。
(在Windows上使用 get-pip 有个小问题:在下载get-pip.py文件时,请重命名这个文件,以确保文件名中不包含”pip”,比如 gp.py。否则会触发pip的检查,导致运行中断。我们正在跟进这个问题,地址是:https://github.com/pypa/pip/issues/5219 )。
新版本pip 10的亮点:
此外,先前宣布的pip内核重组已经开始了。除非你写的代码有导入pip模块(或者你使用了这样的代码),否则这一变化不会对你产生任何影响。如果你受到了影响,请将问题报告给问题代码的作者(推荐他们访问https://mail.python.org/pipermail/distutils-sig/2017-October/031642.html 详情请参阅公告)
感谢为新版本付出辛劳的每个人。社区成员做了许多的贡献 – 有代码方面的,有参与设计讨论的,或者上报bug的。pip开发团队由衷地感谢社区各位所做的贡献。
谢谢
Paul
本文介绍了Python中单下划线和双下划线(”dunder”)的各种含义和命名约定,名称修饰(name mangling)的工作原理,以及它如何影响你自己的Python类。
单下划线和双下划线在Python变量和方法名称中都各有其含义。有一些含义仅仅是依照约定,被视作是对程序员的提示 – 而有一些含义是由Python解释器严格实现。
如果你想知道“Python变量和方法名称中单下划线和双下划线的含义是什么?”,我会尽我所能在这里为你解答。
在本文中,我将讨论以下五种下划线规范和命名约定以及它们如何影响Python程序的行为:
在文章结尾处,你可以找到一个简短的“速查表”,总结了五种不同的下划线命名约定及其含义。
让我们马上开始!
当涉及到变量和方法名称时,单个下划线前缀只有约定本身的含义。 这是对程序员的一个提示 – 意味着Python社区一致认为它应该是什么意思,但程序的行为不受影响。
下划线前缀的含义是向其他程序员表示:以单个下划线开头的变量或方法仅供内部使用。 该约定在PEP 8中有定义。
这不是Python强制规定的。 Python不像Java那样在“私有”和“公共”变量之间有很强的区别。 这就像有人提出了一个小小的下划线警告标志,说:
“嘿,这不是真的要成为类的公共接口的一部分。不去管它就好。“
看看下面的例子:
如果你实例化此类并尝试访问在__init__构造函数中定义的foo和_bar属性,会发生什么情况? 让我们来看看:
你会看到_bar中的单个下划线并没有阻止我们“进入”类并访问该变量的值。
这是因为Python中的单个下划线前缀仅仅是一个约定 – 至少在涉及变量和方法名的时候。
但是,前导下划线的确会影响从模块中导入名称的方式。
假设你在一个名为my_module的模块中有以下代码:
现在,如果使用通配符导入从模块中导入所有名称,则Python不会导入带有前导下划线的名称(除非模块定义了覆盖此行为的__all__列表):
顺便说一下,应该避免通配符导入,因为它们使名称空间中存在哪些名称不清楚。 为了清楚起见,坚持常规导入更好。
与通配符导入不同,常规导入不受前导单个下划线命名约定的影响:
我知道这一点可能有点令人困惑。 如果您遵循PEP 8推荐,避免通配符导入,那么您真正需要记住的只有这个:
单个下划线是一个Python命名约定,表示这个名称是供内部使用的。 它通常不由Python解释器强制执行,仅仅作为对程序员的提示。
有时候,一个变量的最合适的名称已经被一个关键字所采用。 因此像class或def这样的名称不能用作Python中的变量名称。 在这种情况下,您可以附加一个下划线来解决命名冲突:
总之,单个末尾下划线(后缀)是一个约定,用来避免与Python关键字产生命名冲突。 PEP 8解释了这个约定。
到目前为止,我们所涉及的所有命名规范的含义,来自于已达成共识的约定。 而对于以双下划线开头的Python类的属性(包括变量和方法),情况就有点不同了。
双下划线前缀会导致Python解释器重写属性名称,以避免子类中的命名冲突。
这也叫做名称修饰(name mangling) – 解释器更改变量的名称,以便在类被扩展的时候不容易产生冲突。
我知道这听起来很抽象。 因此,我拼凑了一个小小的代码示例来予以说明:
让我们用内置的dir()函数来看看这个对象的属性:
这给了我们一个包含对象属性的列表。 让我们来看看这个列表,并寻找我们的原始变量名称foo,_bar和__baz – 我保证你会注意到一些有趣的变化。
__baz出什么情况了?
如果你仔细观察,你会看到此对象上有一个名为_Test__baz的属性。 这就是Python解释器所做的名称修饰。 它这样做是为了防止变量在子类中被重写。
让我们创建另一个扩展Test类的类,并尝试重写构造函数中添加的现有属性:
现在,你认为foo,_bar和__baz的值会出现在这个ExtendedTest类的实例上吗? 我们来看一看:
等一下,当我们尝试查看t2 .__ baz的值时,为什么我们会得到AttributeError? 名称修饰被再次触发了! 事实证明,这个对象甚至没有__baz属性:
正如你可以看到__baz变成_ExtendedTest__baz以防止意外修改:
但原来的_Test__baz还在:
双下划线名称修饰对程序员是完全透明的。 看看下面的例子来证实这一点:
名称修饰是否也适用于方法名称? 是的,也适用。名称修饰会影响在一个类的上下文中,以两个下划线字符(”dunders”)开头的所有名称:
这是另一个也许令人惊讶的运用名称修饰的例子:
在这个例子中,我声明了一个名为_MangledGlobal__mangled的全局变量。然后我在名为MangledGlobal的类的上下文中访问变量。由于名称修饰,我能够在类的test()方法内,以__mangled来引用_MangledGlobal__mangled全局变量。
Python解释器自动将名称__mangled扩展为_MangledGlobal__mangled,因为它以两个下划线字符开头。这表明名称修饰不是专门与类属性关联的。它适用于在类上下文中使用的两个下划线字符开头的任何名称。
有很多要吸收的内容吧。
老实说,这些例子和解释不是从我脑子里蹦出来的。我作了一些研究和加工才弄出来。我一直使用Python,有很多年了,但是像这样的规则和特殊情况并不总是浮现在脑海里。
有时候程序员最重要的技能是“模式识别”,而且知道在哪里查阅信息。如果您在这一点上感到有点不知所措,请不要担心。慢慢来,试试这篇文章中的一些例子。
让这些概念完全沉浸下来,以便你能够理解名称修饰的总体思路,以及我向您展示的一些其他的行为。如果有一天你和它们不期而遇,你会知道在文档中要查什么。
小知识:什么是Python中的“dunder”?
如果你听过一些经验丰富的Python支持者所做的讲座,或者看过几次会议演讲,你可能已经听说过dunder这个词。 如果你想知道这到底是什么,请查看以下的解释:
在Python社区中,双下划线通常被称为“dunders”。 原因是在Python代码中经常会出现双下划线,并且为了避免下巴肌肉疲劳,Python支持者通常会将“double underscore”缩写为“dunder”。
例如,你会把__baz叫做“dunder baz”。 同样,__init__会被叫做“dunder init”,尽管有人可能认为它应该是“dunder init dunder”。但这只是命名规则中的另一个俏皮话。
这有点像是Python开发者之间的暗号 🙂
也许令人惊讶的是,如果一个名字同时以双下划线开始和结束,则不会应用名称修饰。 由双下划线前缀和后缀包围的变量不会被Python解释器修改:
但是,Python保留了有双前导和双末尾下划线的名称,用于特殊用途。 这样的例子有,__init__对象构造函数,或__call__ — 它使得一个对象可以被调用。
这些dunder方法通常被称为神奇方法 – 但Python社区中的许多人(包括我自己)都不喜欢这种方法。
最好避免在自己的程序中使用以双下划线(“dunders”)开头和结尾的名称,以避免与将来Python语言的变化产生冲突。
按照习惯,有时候单个独立下划线是用作一个名字,来表示某个变量是临时的或无关紧要的。
例如,在下面的循环中,我们不需要访问正在运行的索引,我们可以使用“_”来表示它只是一个临时值:
你也可以在拆分(unpacking)表达式中将单个下划线用作“不关心的”变量,以忽略特定的值。 同样,这个含义只是“依照约定”,并不会在Python解释器中触发特殊的行为。 单个下划线仅仅是一个有效的变量名称,会有这个用途而已。
在下面的代码示例中,我将汽车元组拆分为单独的变量,但我只对颜色和里程值感兴趣。 但是,为了使拆分表达式成功运行,我需要将包含在元组中的所有值分配给变量。 在这种情况下,“_”作为占位符变量可以派上用场:
除了用作临时变量之外,“_”是大多数Python REPL中的一个特殊变量,它表示由解释器评估的最近一个表达式的结果。
这样就很方便了,比如你可以在一个解释器会话中访问先前计算的结果,或者,你是在动态构建多个对象并与它们交互,无需事先给这些对象分配名字:
以下是一个简短的小结或“速查表”,罗列了我在本文中谈到的五种Python下划线规范的含义:
| 模式 | 举例 | 含义 |
| 单前导下划线 | _var | 命名约定,仅供内部使用。 通常不会由Python解释器强制执行(通配符导入除外),只作为对程序员的提示。 |
| 单末尾下划线 | var_ | 按约定使用以避免与Python关键字的命名冲突。 |
| 双前导下划线 | __var | 当在类上下文中使用时,触发”名称修饰“。 由Python解释器强制执行。 |
| 双前导和双末尾下划线 | __var__ | 表示Python语言定义的特殊方法。 避免在你自己的属性中使用这种命名方案。 |
| 单下划线 | _ | 有时用作临时或无意义变量的名称(“不关心”)。 也表示Python REPL中最近一个表达式的结果。 |
原文地址: https://ogmcsrgk5.qnssl.com/vcdn/1/%E4%BC%98%E8%B4%A8%E6%96%87%E7%AB%A0%E9%95%BF%E5%9B%BE/python-top-10-open-source-projects-v-mar-2018-e2ce1d645ec.png
译者:首席IT民工
在过去的一个月中,我们对近250个Python开源项目进行了排名,选出了前十。
我们比较了在此期间有新的发布或是重大发布的项目。Mybridge AI基于多种因素对项目进行排名,以衡量其在专业人员眼中的质量。
开源项目对程序员大有裨益。希望你找到一个有意思的项目,让你有所启发。
Delorean:时间旅行变得容易了[v 1.0] [Github上点赞数:1335个]

Birdseye: 快速、方便、以表达为中心的、使用AST的Python图形化调试器 [Github上点赞数:674个]

Som-tsp: 使用自组织地图技术解决旅行中的销售员所遇到的问题 [Github上点赞数:432个]

Voluptuous:尽管名字有点妖娆,这是一个Python的数据校验库 [Github上点赞数:1066个]

Icecream(冰淇淋):甜甜的,奶油般柔滑的打印调试 [Github上点赞数:530个]

Binance-trader 币安网交易者 (Binance: 区块链资产交易平台): 币安网加密货币交易机器人 (实验性的) [Github上点赞数:590个]

Multidiff: 针对于多个对象或者数据流的二进制(数据)比较工具 [Github上点赞数:188个]

Unimatrix: 可以模拟电影《黑客帝国》中终端显示的Python脚本。默认使用半角片假名的Unicode字符,但可以使用自定义的字符集 [Github上点赞数:558个]

Mypy-protobuf (协议缓冲区):用于从协议缓冲区中生成mypy 根的开源工具 [Github上点赞数:33个]

Lulu: You-get的一个友好分叉(fork), 即爬取网络的无声下载程序 [Github上点赞数:296个]

这些就是每月开源项目的介绍。如果你喜欢这种方式,请按照您的编程技巧阅读我们网站上的每日最佳文章。
作者:Victor Stinner
译者:首席IT民工
作为Python最关键的组成部分之一:GIL(全局解释器锁),我花了4年时间修复了其中的一个令人讨厌的bug。为了修复这个bug,我不得不深挖Git的历史,才找出26年前Guido van Rossum (龟叔,Python创立者) 所做的一处更改。那个时候,线程还是很深奥的东西。
我的故事是这样的。
2014年3月,Steve Dower报告了bug bpo-20891。这个bug发生在“C线程”使用Python C API时:
在Python 3.4rc3版本中,从一个非Python创建的线程中调用PyGILState_Ensure(),并且完全没有调用 PyEval_InitThreads()的情况下,将产生一个致命的退出:
发生致命的Python错误:take_gil:NULL tstate
我的第一个评论是:
以我之愚见,这是PyEval_InitThreads()中的一个Bug。
2年的时间里,我完全不记得这个bug了。 2016年3月,我修改了Steve的测试程序,使其与Linux兼容(该测试是为Windows编写的)。 我成功地重现了我电脑上的错误,并且为PyGILState_Ensure()写了一个修复程序。
一年后,2017年11月,卡辛斯基问道:
此修复发布了吗? 我在更新日志中找不到…
哎呀,我又完全忘记了这个问题! 这一次,我不仅安装了我的PyGILState_Ensure()修复,还编写了单元测试test_embed.test_bpo20891():
好的,这个bug现在已经在Python 2.7, 3.6 和master(将来的3.7)中得到解决。 在3.6和master版本中,此修复带有单元测试。
我的主分支的修复,提交b4d1e1f7:
于是我关闭了问题bpo-20891 …
一切都很好……但一周后,我注意到我新增加的单元测试在macOS buildbots上发生了随机崩溃。 我成功地手动重现了这个bug,第三次运行时崩溃的例子:
macOS上的test_embed.test_bpo20891()在PyGILState_Ensure() 中显示有竞态条件(race condition):GIL锁本身的创建…没有被加锁保护! 添加一个新的锁来检查Python是否有GIL锁,好像没有意义…
我提出了PyThread_start_new_thread()的一个不完整的修复:
我发现有一个修复是管用的:在PyThread_start_new_thread()中调用PyEval_InitThreads()。 那么,一旦生成第二个线程就会创建GIL锁。 当两个线程正在运行时,GIL不能再创建。 至少,用python代码不可以建。 如果一个线程不是由Python产生的话,此修复不能解决这个问题,但是这个线程调用了PyGILState_Ensure()。
Antoine Pitrou问了一个简单的问题:
为什么不在解释器初始化时总是调用PyEval_InitThreads()? 有什么缺点吗?
感谢git blame和git log,我发现了“按需”创建GIL的代码,来自于26年前做出的改变!
我的猜测是,动态创建GIL的目的是为了减少GIL的“开销”。这些GIL用于那些只使用单个Python线程的应用程序(永远不会产生新的Python线程)。
幸运的是,Guido van Rossum在我附近,能够对基本原理加以阐述:
是的,最初的理由是线程是深奥的,不为大多数代码所使用,并且当时我们一定觉得:总是使用GIL会导致(微小的)速度放缓,并增加由于GIL代码中的错误而导致崩溃的风险。 我很高兴得知我们不再需要担心这一点,并且可以始终对其进行初始化。
我提出了Py_Initialize()的第二个修复,以便在Python启动时始终创建GIL,并且不再“按需”,以防止出现竞态条件的风险:
Nick Coghlan问我是否可以通过性能基准测试我的补丁。 我在我的PR 4700上运行pyperformance。差异至少5%:
哦,5个基准比较慢。 Python中性能退步是不受欢迎的:我们正在努力让Python变得更快!
我没有想到5个基准测试会变慢。 我需要进一步的调查,但时间不够。也许是我太害羞,或者羞于承担导致性能退步的责任。
在圣诞节假期之前,我没有做任何决定,而test_embed.test_bpo20891()在macOS buildbots上仍然是随机失败。 在离开两个星期之前,我对于触及Python的关键部分,即GIL,并没有太多把握。 所以我决定,等到我回来之前,先跳过test_bpo20891()。
没有圣诞礼物给你了:Python 3.7。
在2018年1月底,我再次运行了那5个由于我的PR(Pull request)而变慢的基准测试。 我使用了CPU隔离,在我的笔记本电脑上手动运行这些基准测试:
好吧,它证实了,依照Python性能基准套件,我的第二个修复对性能没有显著的影响。
我决定将我的修复程序推送到master分支,提交2914bb32:
然后我在master分支上重新启用了test_embed.test_bpo20891()。
Antoine Pitrou认为,不应该合并Python 3.6的backport (注:backport是将一个软件的补丁应用到比此补丁所对应的版本更老的版本的行为):
我不这么认为。 人们可能已经调用PyEval_InitThreads()。
Guido van Rossum也不想把这一修改做backport。 所以我只从3.6的分支中删除了test_embed.test_bpo20891()。
由于相同的原因,我没有将我的第二个修复应用于Python 2.7。 而且,Python 2.7没有单元测试,因为它很难backport。
至少,Python 2.7和3.6获得了我的第一个PyGILState_Ensure()修复。
在少数案例中,Python仍然存在一些竞态条件。 当一个C线程开始使用Python API时,在创建GIL时就可以发现这样的Bug。 我推出了第一个修复程序,但在macOS上发现了一个新的不同的竞态条件。
我不得不深入研究Python GIL的历史(1992年)。 幸运的是,Guido van Rossum也能够阐述其基本原理。
在基准测试出现故障后,我们同意修改Python 3.7,以便始终创建GIL,而不是按需创建GIL。 该变化对性能没有显著的影响。
我们还决定让Python 2.7和3.6保持不变,以防止任何回退风险:可以继续按需创建GIL。
我花了4年的时间修复了Python GIL中的一个令人讨厌的bug。 在接触Python中如此关键的部分时,我从未自信满满。 现在,我很高兴这个bug被我们甩在了身后:现在,它已经在未来的Python 3.7中完全修复了!
完整的故事见bpo-20891。 感谢帮助我解决这个Bug的所有开发人员!
作者:Andrew Brust
原文地址:http://www.zdnet.com/article/can-data-science-notebooks-get-real-jupyter-lab-releases-to-users/
译者:首席IT民工
副标题:Jupyter 笔记本已经突破了他们“展示和讲解”的角色,正变得更适合数据工程师使用。JupyterLab 会把这些笔记本升级成一款企业级工具吗?
现如今,业内人士相信,数据和分析都可以借助人工智能的服务来完成。鉴于此,作为数据科学家看来最受欢迎的数据处理工具 — 笔记本, 相关的介绍很多。这一领域的巨头有 Apache Zeppelin,和更加著名的 Jupyter (前身是iPython)。如果你的工作平台是Databricks,通常你最后都会使用他们自有品牌的笔记本。即便如此,这些笔记本都和Jupyter兼容。
可以把笔记本看成是一个你存放代码并添加注释的地方。不过,也许更准确地说法是,笔记本是存放大量注释,并用代码加以修饰的地方。无论你想要多么尖锐,有了笔记本,你可以在Markdown格式的富文本中,穿插任意语言的代码,本地运行,然后以文本、表格或是图形的方式来查看结果。如果你足够细致的话,甚至可以把这些资产拼凑成某个穷人的仪表盘。
笔记本的问题在于,相比于生产环境里的数据工程工作,它更适合实验性质的数据科学工作。虽然这只是我自己的看法,我却坚持这么认为。笔记本更多的是关于演示而非开发,而且缺少了很多IDE(集成开发环境)比如Eclipse, PyCharm, Visual Studio, RStudio的好的功能。
不过,凡事总有变化。Jupyter 笔记本起初是Python代码的专属工具,也是Anaconda的一部分。Anaconda包含了主要的Python发布,一直致力于通过JupyterLab增强Jupyter笔记本的功能,使其更像是一个IDE。本周早些时候,JupyterLab,这款受到长期吹捧的工具终于发布,可供开发者使用。考虑到这是个不大却很重要的里程碑事件,我决定下载JupyterLab,跑一跑,并看看怎么样。整体而言,我印象深刻。

JupyterLab,一个基于R语言的笔记本和它的几种可视化结果,显示在了同一个版面上
JupyterLab是包含了Jupyter(笔记本)的超集。所以,在Jupyter笔记本中能做的事情,在JupyterLab中都可以做。而且能做的事情更多。
首先,一些笔记本能够提供的,比如Tab键语法完成,Shift-Tab键查看对象工具的提示这些功能依然都在。比起独立的Jupyter 笔记本来说,JupyterLab的功能更强:在Tab键完成时,提供匹配条目的类型的额外信息;在工具提示中,也提供对象相关的更多信息。有了这种基于上下文的辅助功能,开发者不必老是切换上下文,以便把事情给想清楚。
开发者们也可以工作在偏命令行风格的编程模式下,即,在控制台(而不是笔记本)内交互地运行他们的代码。控制台是与Jupyter内核建立的实时会话(实际上语言解释器是在笔记本后台完成代码的执行),所以,开发者可以先在控制台环境中运行代码,然后在以文本和图形为主的文档(显示在笔记本中)中插入这些代码。
然而,JupyterLab远远超越了笔记本的功能。它允许开发者打开多种格式的文件,这些文件中包含了他们可能用到的,或者由代码产生的数据和其他资源。文件类型包括:支持语言的源代码文件,纯文本、CSV(和其他分隔符的文本格式)、JSON、各类图片、甚至是PDF格式的文件。查看器和编辑器则包括:全功能的文本编辑器,图片查看器,表格数据查看器,带树形视图的JSON查看器,以及适用Vega, Vega-Lite和VDOM文件的查看器。
有时候,某些特定的文件适用于多个查看器。比如说,JSON和CSV文件都能以纯文本方式打开。不过其实,JSON也可以用树形视图查看器打开,CSV也可以用表格查看器打开。Jupyter支持用多个编辑器同时打开这样的文件,并且保持多个视图间的同步,以便在一个编辑器中所做的修改,显示在另一个编辑器中。
多视图模型也适用于笔记本。比如,只要在笔记本内已显示的图像上单击右键,并从菜单中选择“为输出建立新视图”,多个图像就可以并排地以各自视图的方式显示出来,包括笔记本的传统视图。
一点点拖放就可以办到。支持在近似水平或垂直的区域中,显示多个笔记本、输出结果和文件查看器。区域之间用分隔列分开,每个区域容纳了多个标签文档,每个文档支持单独上下滚动。一旦你习惯于创建这种布局,你甚至能够排列出如上图所示的仪表盘风格的布局。
需要承认的是,这些养眼的东西有时候会让人分心。所以,JupyterLab支持用户在这种分块布局和单文档视图之间进行切换。在单文档视图中,活动文档会占据JupyterLab浏览器页或窗口的整个编辑区域。
JupyterLab支持Chrome,Firefox和Safari浏览器。据我有限的测试,除了单文档视图会导致严重的显示异常以外(我确认该异常在Chrome中不存在),JupyterLab在Windows 10 Edge浏览器中也运行良好。

JupyterLab启动器
类似Jupyter, JupyterLab支持多语言,前提是这些语言的内核已安装好。如上图所示,启动器允许用户选择一种语言来创建新的笔记本,或是控制台。默认已安装了Python内核。据我测试,我成功地安装了R和Node/JavaScript内核。
下图显示了一个基于Node.js的笔记本,以及其中一种显示结果的单独视图。

归功于其对多种技术的组合,JupyterLab的安装可以很复杂。首先,在你的系统上安装Anaconda Python,它会安装Jupyter的核心文件。接下来,安装R内核的支持文件。然后,你可以下载JupyterLab,分别安装其他语言和Jupyter内核。我是这么安装Node.js内核的,做了好几步才弄对。去掉范例笔记本则耗费了额外的研究时间,安装那些提供代码支持所必须的模块也是如此。
安装也许有些难度,但并不高深(不算数据科学)。我曾经做过程序员,现在依然爱倒腾各种工具,所以我对这些东西有种本能。但是,我的编码技能退化了,也不再是使用工具的好手了。如果我可以办到,那么任何有基本技能和对JupyterLab感兴趣的人也可能没什么问题。不过,耐心和空余时间还是需要的。如果有一个主要安装程序,则会减少很多麻烦。
对于需要Jupyter用户来说,由于很多云服务(包括微软HDInsight,亚马逊SageMaker,及谷歌的Cloud DataLab)中已经包含了Jupyter,安装不成问题。不知道这些包含Jupyter的服务和产品中也会包含JupyterLab吗?但愿如此,因为这样做会让这些平台上的数据工程体验更好。
基于Web浏览器的开发工具富有创新性,但也有其局限性。对于这个难题,Jupyter是一个好榜样。JupyterLab有助于超越这些局限,又不失创新性和便利性。让我们希望它在生态系统中的应用越来越火。






